Download:
Abstract:
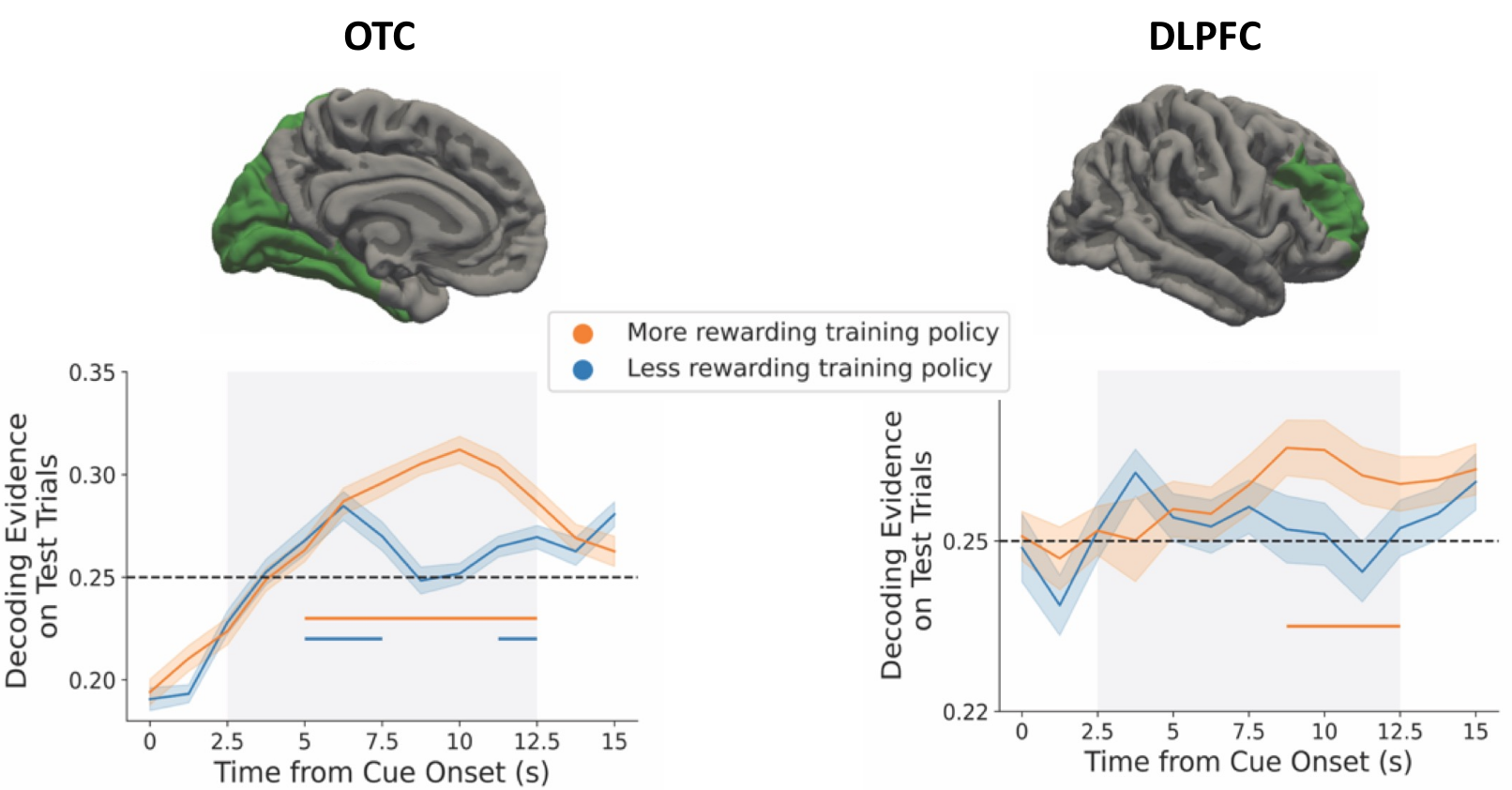
Generalization from past experience is an important feature of intelligent systems. When faced with a new task, one efficient computational approach is to evaluate solutions to earlier tasks as candidates for reuse. Consistent with this idea, we found that human participants (n = 38) learned optimal solutions to a set of training tasks and generalized them to novel test tasks in a reward-selective manner. This behavior was consistent with a computational process based on the successor representation known as successor features and generalized policy improvement (SF&GPI). Neither model-free perseveration or model-based control using a complete model of the environment could explain choice behavior. Decoding from functional magnetic resonance imaging data revealed that solutions from the SF&GPI algorithm were activated on test tasks in visual and prefrontal cortex. This activation had a functional connection to behavior in that stronger activation of SF&GPI solutions in visual areas was associated with increased behavioral reuse. These findings point to a possible neural implementation of an adaptive algorithm for generalization across tasks.
Neural activation of previously reinforced policy on novel task
Citation
Hall-McMaster, S., Tomov, M. S., Gershman, S. J., Schuck, N. W. (2025). “Neural evidence that humans reuse strategies to solve new tasks.” PLOS Biology, 23(6), e3003174. https://doi.org/10.1371/journal.pbio.3003174.
@article{hall2025neural,
author = {Hall-McMaster, Sam AND Tomov, Momchil S. AND Gershman, Samuel J. AND Schuck, Nicolas W.},
journal = {PLOS Biology},
publisher = {Public Library of Science},
title = {Neural evidence that humans reuse strategies to solve new tasks},
year = {2025},
month = {06},
volume = {23},
pages = {1-31},
abstract = {Generalization from past experience is an important feature of intelligent systems. When faced with a new task, one efficient computational approach is to evaluate solutions to earlier tasks as candidates for reuse. Consistent with this idea, we found that human participants (n = 38) learned optimal solutions to a set of training tasks and generalized them to novel test tasks in a reward-selective manner. This behavior was consistent with a computational process based on the successor representation known as successor features and generalized policy improvement (SF&GPI). Neither model-free perseveration or model-based control using a complete model of the environment could explain choice behavior. Decoding from functional magnetic resonance imaging data revealed that solutions from the SF&GPI algorithm were activated on test tasks in visual and prefrontal cortex. This activation had a functional connection to behavior in that stronger activation of SF&GPI solutions in visual areas was associated with increased behavioral reuse. These findings point to a possible neural implementation of an adaptive algorithm for generalization across tasks.},
number = {6},
doi = {10.1371/journal.pbio.3003174},
url = {https://doi.org/10.1371/journal.pbio.3003174}
}